这篇博客的主要内容将围绕如何训练你的第一个神经网络并完成简单的分类任务
环境搭建
我们选择Pycharm作为开发的IDE环境,使用conda管理虚拟环境。
Step 1 下载Anaconda
前往官网下载Anaconda,并完成安装
conda官网
安装完成后,打开命令行终端并输入下面指令
conda -V若显示conda系统信息,则已完成安装
Step 2 创建虚拟环境
输入下面终端指令,创建python虚拟环境
// 查看虚拟环境
conda env list
// 创建虚拟环境
// 'myenv'替换成你喜欢的虚拟环境名称
// python=3.5表示指定python版本为3.5
conda create --name myenv python=3.5
// 再次查看虚拟环境,你应该会看到刚刚新建的环境
conda env list环境创建后,可以在你希望进行python开发的文件位置打开一个终端
输入下面的指令,激活python虚拟环境(指终端进入python控制台)
// 'myenv'替换成你希望激活的环境名称
activate myenv
// 可以使用这个指令离开虚拟环境
deavtivete
// 这个指令可以删除虚拟环境
conda remove --name myenv在虚拟环境中,可以应用一些conda指令:
conda list //查看有什么包
conda install xxxx // 安装特定包Step 3 安装pycharm
前往官网安装pycharm
官网
安装时可以选择将vscode风格和插件一键移植到pycharm
安装完成后,新建一个项目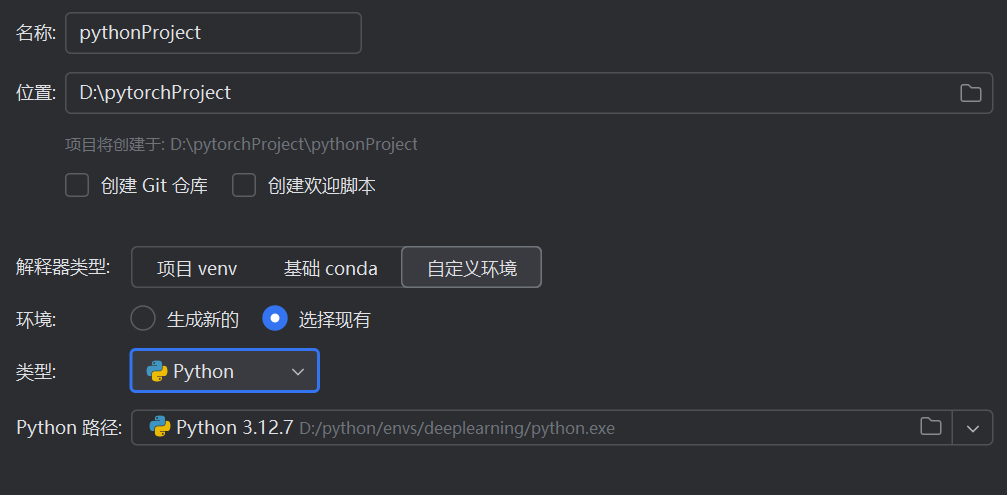
python路径选择你刚创建的虚拟环境,选择其中的python.exe文件即可
至此,你已经完成全部环境配置,可以尝试运行简单python程序
新建python程序,输入下面的代码并运行,检查解释器是否完成配置
print(Hello World)训练你的第一个模型
我们选择从Kaggle上获取开源数据,进行网络训练。
Step 1 下载数据集
前往官网Bird Speciees Dataset
直接下载数据集并解压到工作目录
你可以检查文件夹中的各个图片,应该是六种特征明显的鸟类。
检查无误后我们将开始编写程序。
Step 2 数据预处理
一般而言,我们需要对输入的图像文件进行一些处理,包括
- 图像对齐(224x224)
- 将类型转换为tensor张量
- 将像素值归一化到0~1
- (可选)将图片像素值均值处理成0,保持一定方差
但本次我们不进行这样的操作,因为预处理的主要目的是加快训练速度和提高性能,
而这个数据集特征极其明显,因此不进行预处理对结果影响不大。
Step 3 分割数据集
首先,下面是你需要引入的所有包,在文件开头写入即可
(注意,大部分包你应该都没下载过,需要通过包管理下载,但不用担心,先往下看)
import torch
import os
from PIL import Image
from sklearn.preprocessing import LabelEncoder
from sklearn.model_selection import train_test_split
from sympy import viete
from torch.utils.backcompat import keepdim_warning
from torchvision.transforms import ToTensor
from torch import cuda, nn, optim
import torch.nn.functional as F
from torch.utils.data import DataLoader
from tqdm import tqdmpycharm拥有快速修复功能,如果你发现代码中出现红色波浪,将鼠标放在其上,会出现快速修复功能,点击后pycharm会自动调包管理插件,下载所需的包,并完成import。
因此,你可以轻松地完成所需包的下载。
接下来进行数据集分割,将其分成训练集、测试集和验证集。
path = "Bird Species Dataset"
data_dir = path
images = []
labels = []
# 按顺序读取所有图像文件
for root, dirs, files in os.walk(data_dir):
for f in files:
if f.endswith('.jpg') or f.endswith('.png'):
file_path = os.path.join(root, f)
# 子目录名称作为标签
label = os.path.basename(root)
images.append(file_path)
labels.append(label)
# 将字符串的label编码成数字
le = LabelEncoder()
encoded_labels = le.fit_transform(labels)
# 第一步:先将整个数据集划分为训练集和其他(这里包括验证集+测试集)
train_images, temp_images, train_labels, tmp_labels = train_test_split(images, encoded_labels, test_size=0.3, random_state=42, stratify=labels) # 70% 训练, 30% 其他
# 第二步:从剩余的数据集中再划分出验证集和测试集
val_images, test_images, val_labels, test_labels = train_test_split(temp_images, tmp_labels, test_size=0.5, random_state=42, stratify=tmp_labels) # 15% 验证, 15% 测试
print(f"训练集大小: {len(train_images)}")
print(f"验证集大小: {len(val_images)}")
print(f"测试集大小: {len(test_images)}")你可以运行文件,查看数据集大小是否正确
Step 4 构建网络
本次实验我们分别构造全连接网络和卷积网络,并比较性能差别
两个网络分别继承nn.Module这个基类(pytorch包内已经写好了)
super.init()表示使用父类的初始化,可以就理解为初始化
nn.Linear和nn.Conv2d也都是pytorch已经实现的连接层和卷积层
nn.MaxPool2d则是池化层,采用2x2的下采样
F.relu也是pytorch已经实现的函数,我们在开头已经导入了
class Liner(nn.Module):
def __init__(self, input_size = 3*224*224, hidden_size=100):
super(Liner, self).__init__()
self.fc1 = nn.Linear(input_size, hidden_size)
self.fc2 = nn.Linear(hidden_size, 6)
def forward(self, x):
x = x.view(x.size(0), -1)
x = self.fc1(x)
x = F.relu(x)
x = self.fc2(x)
return x
class CNN(nn.Module):
def __init__(self, num_classes = 6, in_channels = 3):
super(CNN, self).__init__()
self.conv1 = nn.Conv2d(in_channels = in_channels , out_channels = 16, kernel_size=3, stride=1, padding=1)
self.pool1 = nn.MaxPool2d(kernel_size=2, stride=2)
self.conv2 = nn.Conv2d(in_channels = 16 , out_channels = 32, kernel_size=3, stride=1, padding=1)
self.fc1 = nn.Linear(in_features = 32 * 112 * 112, out_features = num_classes)
def forward(self, x):
x = F.relu(self.conv1(x))
x = self.pool1(x)
x = F.relu(self.conv2(x))
x = x.view(x.size(0),-1)
x = self.fc1(x)
return x至此,我们网络的结构和向前传播已经构造完成。
由于pytorch不需要我们显式实现向后传播计算梯度,而是在后续计算过程生成计算图,来计算向后传播的梯度。所以整个网络已经搭建完成。
Step 5 训练网络
我们现在已经拥有了一组图片的tensor张量以及和它一一对应的标签,但是我们不能把这么多图片一起全都扔进网络训练,因为我们的显存(如果是CPU训练就是CPU内存)没有这么大(你可以全都扔进去试试:))。
所以我们需要在每轮训练时从train样本中不重复的抽取一组,来进行向前传播和向后传播。
我们称为batch_size。
我们同样借助torch来实现。
定义一个鸟的数据类,继承自torch的Dataset。
transform主要是讲图像的类型转换为tensor,便于前面定义的网络使用。
getitem是主要使用的方法,就是随机生成索引,并取出images和labels对应的数据。
使用这个类的好处在后面使用的时候就可以看出来,它可以自动随机取样,并且循环调用,且不会重复取样,可以保证一轮训练恰好用完所以train样本。
class BirdDataset(torch.utils.data.Dataset):
def __init__(self, images, labels, transform=None):
self.images = images
self.labels = labels
self.transform = transform if transform else ToTensor()
def __len__(self):
return len(self.images)
def __getitem__(self, index):
img_path = self.images[index]
label = self.labels[index]
label = int(label)
# 加载图像并转换为PIL图像
image = Image.open(img_path)
# 应用变换
if self.transform:
image = self.transform(image)
# 返回图像数据和对应标签
return image, label接下来我们调用上面写的网络类和数据集类,来进行训练。
# 使用GPU训练,如果需要的话要自行配置cuda,第一次训练可以先不用
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 每次采样大小,一般128和64是个合适的值
batch_size = 64
# 训练轮数,train中所有样本训练过一次算一轮
num_epochs = 10
# 学习率,一个较大的学习率会导致振荡,1e-3和1e-4是个合适的值
learning_rate = 1e-3
# 定义我们的模型
model = CNN().to(device)
# 下面是全连接网络,切换网络时改变注释即可
# model = Liner().to(device)
# 采用torch包内的交叉熵损失函数
# 评估你模型的优劣,为下一步训练提供更新依据
criterion = nn.CrossEntropyLoss()
# 梯度更新器,选用Adam方法,这是一个比较快速的梯度下降方法
# 可以理解为他会根据你前一步的损失,考虑多大程度地改变模型参数
optimizer = optim.Adam(model.parameters(), lr=learning_rate)
# 制作数据集加载器,DataLoader同样是torch包内写好的
train_data = BirdDataset(train_images, train_labels, transform=ToTensor())
train_loader = DataLoader(dataset = train_data, batch_size=batch_size, shuffle=True)
test_data = BirdDataset(test_images, test_labels, transform=ToTensor())
test_loader = DataLoader(dataset = test_data, batch_size=batch_size, shuffle=True)
# 开始训练
# 两层循环,第一层训练轮数
# 第二层是对train进行的反复采样直到遍历完train
for epoch in range(num_epochs):
print(f"Epoch [{epoch + 1}/{num_epochs}]")
# enumerate用于遍历train_loader这个序列
# 因为train_loader本身只能根据索引采样数据,所以需要enumerate提供遍历的索引
for batch_index, (data, targets) in enumerate(train_loader):
image = data.to(device)
label = targets.to(device)
# 向前传播,计算得分,同时清空梯度,开始产生梯度计算图
optimizer.zero_grad()
score = model(image)
loss = criterion(score, label)
# 向后传播
loss.backward()
# 更新模型参数
optimizer.step()
print("loss: ", loss.item())
# 下面是我们写的观察模型准确率的函数
train_accuracy = check_accuracy(train_loader, model, n = 1)
test_accuracy = check_accuracy(test_loader, model, n = 2) 至此,整个模型训练就已经完成,下面附上检验正确率的函数,请你在模型训练前先对其声明
def check_accuracy(loader, model, n):
num_correct = 0
num_samples = 0
model.eval()
if n == 1:
print("Checking accuracy on training data")
if n == 2:
print("Checking accuracy on test data")
if n == 3:
print("Checking accuracy on validation data")
with torch.no_grad():
for x, y in loader:
x = x.to(device)
y = y.to(device)
scores = model(x)
_, predictions = scores.max(1)
num_correct += (predictions == y).sum()
num_samples += predictions.size(0)
# Calculate accuracy
accuracy = float(num_correct) / float(num_samples) * 100
print(f"Got {num_correct}/{num_samples} with accuracy {accuracy:.2f}%")
model.train()
return accuracy最后,你可以用你的模型对验证集进行预测,评估模型优劣
val_data = BirdDataset(val_images, val_labels, transform=ToTensor())
val_loader = DataLoader(dataset = val_data, batch_size=batch_size, shuffle=True)
check_accuracy(val_loader, model, n = 3 )如果没有问题的话,你应该得到一个对训练集100%准确率,对测试集80%+接近90%的准确率。
Step 6 探究全连接网络
我们已经训练出了一个卷积网络,现在我们来探究一下全连接网络的效果。
使用完卷积网络后,你可以切换到全连接网络进行训练,观察效果。
你应该会发现,全连接网络的准确率很难超过60%。
完整代码
import torch
import os
from PIL import Image
from sklearn.preprocessing import LabelEncoder
from sklearn.model_selection import train_test_split
from sympy import viete
from torch.utils.backcompat import keepdim_warning
from torchvision.transforms import ToTensor
from torch import cuda, nn, optim
import torch.nn.functional as F
from torch.utils.data import DataLoader
from tqdm import tqdm
def check_accuracy(loader, model, n):
num_correct = 0
num_samples = 0
model.eval()
if n == 1:
print("Checking accuracy on training data")
if n == 2:
print("Checking accuracy on test data")
if n == 3:
print("Checking accuracy on validation data")
with torch.no_grad():
for x, y in loader:
x = x.to(device)
y = y.to(device)
scores = model(x)
_, predictions = scores.max(1)
num_correct += (predictions == y).sum()
num_samples += predictions.size(0)
# Calculate accuracy
accuracy = float(num_correct) / float(num_samples) * 100
print(f"Got {num_correct}/{num_samples} with accuracy {accuracy:.2f}%")
model.train() # Set the model back to training mode
return accuracy
class Liner(nn.Module):
def __init__(self, input_size = 3*224*224, hidden_size=100):
super(Liner, self).__init__()
self.fc1 = nn.Linear(input_size, hidden_size)
self.fc2 = nn.Linear(hidden_size, 6)
def forward(self, x):
x = x.view(x.size(0), -1)
x = self.fc1(x)
x = F.relu(x)
x = self.fc2(x)
return x
class CNN(nn.Module):
def __init__(self, num_classes = 6, in_channels = 3):
super(CNN, self).__init__()
self.conv1 = nn.Conv2d(in_channels = in_channels , out_channels = 16, kernel_size=3, stride=1, padding=1)
self.pool1 = nn.MaxPool2d(kernel_size=2, stride=2)
self.conv2 = nn.Conv2d(in_channels = 16 , out_channels = 32, kernel_size=3, stride=1, padding=1)
self.fc1 = nn.Linear(in_features = 32 * 112 * 112, out_features = num_classes)
def forward(self, x):
x = F.relu(self.conv1(x))
x = self.pool1(x)
x = F.relu(self.conv2(x))
x = x.view(x.size(0),-1)
x = self.fc1(x)
return x
class BirdDataset(torch.utils.data.Dataset):
def __init__(self, images, labels, transform=None):
self.images = images
self.labels = labels
self.transform = transform if transform else ToTensor()
def __len__(self):
return len(self.images)
def __getitem__(self, index):
img_path = self.images[index]
label = self.labels[index]
label = int(label)
# 加载图像并转换为PIL图像
image = Image.open(img_path)
# 应用变换
if self.transform:
image = self.transform(image)
# 返回图像数据和对应标签
return image, label
path = "Bird Species Dataset"
# 假设您的图片都存储在一个名为 'data' 的文件夹下
data_dir = path
images = []
labels = []
writer = SummaryWriter()
for root, dirs, files in os.walk(data_dir):
for f in files:
if f.endswith('.jpg') or f.endswith('.png'):
file_path = os.path.join(root, f)
# 子目录名称作为标签
label = os.path.basename(root)
images.append(file_path)
labels.append(label)
le = LabelEncoder()
encoded_labels = le.fit_transform(labels)
# 第一步:先将整个数据集划分为训练集和其他(这里包括验证集+测试集)
train_images, temp_images, train_labels, tmp_labels = train_test_split(images, encoded_labels,
test_size=0.3, random_state=42, stratify=labels) # 70% 训练, 30% 其他
# 第二步:从剩余的数据集中再划分出验证集和测试集
val_images, test_images, val_labels, test_labels = train_test_split(temp_images, tmp_labels,
test_size=0.5, random_state=42, stratify=tmp_labels) # 15% 验证, 15% 测试
print(f"训练集大小: {len(train_images)}")
print(f"验证集大小: {len(val_images)}")
print(f"测试集大小: {len(test_images)}")
train_data = BirdDataset(train_images, train_labels, transform=ToTensor())
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
batch_size = 64
num_epochs = 10
learning_rate = 1e-3
model = CNN().to(device)
# model = Liner().to(device)
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=learning_rate)
train_loader = DataLoader(dataset = train_data, batch_size=batch_size, shuffle=True)
test_data = BirdDataset(test_images, test_labels, transform=ToTensor())
test_loader = DataLoader(dataset = test_data, batch_size=batch_size, shuffle=True)
for epoch in range(num_epochs):
print(f"Epoch [{epoch + 1}/{num_epochs}]")
for batch_index, (data, targets) in enumerate(train_loader):
image = data.to(device)
label = targets.to(device)
optimizer.zero_grad()
score = model(image)
loss = criterion(score, label)
loss.backward()
optimizer.step()
print("loss: ", loss.item())
train_accuracy = check_accuracy(train_loader, model, n = 1)
test_accuracy = check_accuracy(test_loader, model, n = 2)
val_data = BirdDataset(val_images, val_labels, transform=ToTensor())
val_loader = DataLoader(dataset = val_data, batch_size=batch_size, shuffle=True)
check_accuracy(val_loader, model, n = 3 )